通过 BPM 挑选合适的歌曲
注意
本篇博客所演示的爬虫程序仅用于学习研究,请勿用于窃取数据。
相信有很多人跟我一样,出门活动时喜欢戴着耳机听歌,却难以应付以下两个问题:
- 歌单里的歌浩如烟海,每次听歌前都需要花费很长时间选歌。
- 喜欢顺着歌曲的节奏迈步(无论是走路还是跑步),但是切歌会导致节奏混乱。
因此,这篇博客应运而生。我将以 Lovelive! 系列 的歌曲为例,讲述如何编写一个 Python 爬虫,获取歌曲的 BPM 数据,并利用该数据挑选出具有合适节奏的歌曲。
准备
以下准备项目默认读者已具有,在本篇博客中不再赘述。
- Python 运行环境
- 基础 HTML 知识
- 有歌曲 BPM 数据的网站(本篇博客以 LLWiki 为例)
网站分析
在编写爬虫之前,分析目标网站的结构是必要的。
我的目标是:获取 Lovelive! 系列所有歌曲的 BPM 数据(截至 2024.06.27)。那么就按图索骥,从“歌曲分类”的页面开始。
第一步:歌曲分类页面
点击F12,我们发现按字母排列的子分类 栏是由一个个<div class="mw-category-group">的块包裹着的,这就有了定位网页元素的线索。
我们希望按团体进行歌曲的搜索,于是找到 L 栏,里面一个<li>就代表了一项;每个<li>里面有且仅有一个链接元素,即<a href="...">,这样就成功定位到了下一级网页的链接了。
第二步:团体歌曲页面
用同样的方法,将单首歌曲的信息页面定位到各个<div class="mw-category-group">下的<li>中唯一的链接上。
注
第一项<div class="mw-category-group">下的链接指向歌曲列表页面,需要跳过。
第三步:歌曲信息页面
你会发现示例页面没有 BPM 数据(截至 2024.06.27),这是因为歌曲较新还未上线或网站维护人员没有及时更新。
在有 BPM 数据的页面里,我们发现右侧歌曲的信息栏在一个<table class="infoboxtemplate">的表格里面;继续往下搜索就能看到,BPM 数据也在其中的一个<tr>项里。
对于没有 BPM 数据的页面,那就没办法了。甚至还需要反过来排除这类数据😡
编写爬虫
我们利用 Python 中的requests和lxml库来编写爬虫,并对网页元数据进行解析。代码仅供参考。
提示
如果你没有安装这两个库,请先运行库安装命令:
pip install requests lxmlconda install requests lxml:::
为了有更清晰的组织逻辑,接下来将逐个实现对应网站分析步骤的函数。
获取页面信息
该函数实现的功能是:用 get 请求访问一个网页的元数据,是后面几个函数的基础。
我们先修改爬虫的headers信息,将里面的User-Agent字段替换成用户自己的请求头。
接着,我们先用time库里的time.sleep()方法为请求操作设置一个合适的延迟,再用requests.get()方法获取指定 url 的信息,并返回该页面 HTML 的元数据。
headers = {'User-Agent': '...'}
def get_html(url):
time.sleep(0.7)
response = requests.get(url, headers=headers)
if response.status_code != 200:
print('Error:', response.status_code)
exit(1)
return response.text相关信息
爬虫程序本质上是模拟人类访问网页,只是它访问的速度比人类快了不止一个数量级。因此,许多网站为了防止爬虫的高频次访问导致服务器瘫痪(DoS 攻击也是这个原理),会拒绝“一眼看上去就不是人”的用户访问请求。
这就是为什么我们要先指定爬虫头部信息里的User-Agent,为什么我们要让get请求延迟一段时间——这让我们的爬虫看起来更像人。
获取团体列表
该函数实现的功能是:从歌曲分类页面获取各团体的页面链接。
我们拿到页面的元数据之后,基于 网站分析中得到的结果,解析并提取想要的所有链接即可。
这里用Xpath表达式进行路径解析。用到的 Xpath 语法如下:
//...:该元素下所有的...元素/...:该元素下一级中的...元素@...:指定...属性[...]:对该元素进行筛选,一般结合@使用。如[@class="..."]text():文本数据
相关信息
Xpath 语法还支持更复杂的表达式,读者有兴趣可以深入学习。参见 官网。
def get_groups(url):
html = get_html(url)
root = etree.HTML(html)
divs = root.xpath('//div[@class="mw-category-group"]')
for d in divs:
t = d.xpath('./h3/text()')[0]
if t == 'L':
items = d.xpath('./ul/li//a/@href')
return items获取歌曲列表
该函数实现的功能是:从团体歌曲页面获取该团体所有歌曲的曲名和对应信息的页面链接。
同样借助 网站分析中得到的结果进行代码编写。
由于页面下的第一项指向歌曲列表页面,故在遍历时需要跳过。
def get_songs(url):
html = get_html(url)
root = etree.HTML(html)
divs = root.xpath('//div[@class="mw-category-group"]')
items = []
titles = []
for i in range(len(divs)):
if i == 0:
continue
d = divs[i]
items.extend(d.xpath('./ul/li//a/@href'))
titles.extend(d.xpath('./ul/li//a/text()'))
return items, titles获取歌曲 bpm 值
该函数实现的功能是:从歌曲信息页面获取该曲目的 BPM 值。
同样借助 网站分析中得到的结果进行代码编写。
对于没有 BPM 值的歌曲,我选择用"NO_BPM"进行占位;我还再次获取了曲名,目的是为了方便在控制台打印输出,以确认对应的曲名和 BPM 是否对应,以及程序是否正常工作。
def get_bpm(url):
html = get_html(url)
root = etree.HTML(html)
infotable = root.xpath('//table[@class="infoboxtemplate"]')[0]
info = ['NO_TITLE', 'NO_BPM']
for tr in infotable.xpath('./tbody/tr'):
ths = ''.join(tr.xpath('./th//text()[not(ancestor::style)]'))
if ths.strip() == '歌曲原名':
info[0] = ''.join(tr.xpath('./td//text()')).strip()
if ths.strip() == 'BPM':
info[1] = ''.join(tr.xpath('./td//text()')).strip()
return info统合并保存数据
该函数实现的功能是:爬取所有歌曲的 BPM 值并进行存储。
def get_all_bpm():
main_url = 'https://llwiki.org'
# start from "Catagory: 歌曲"
origin_url = main_url + '/zh/Category:%E6%AD%8C%E6%9B%B2'
groups = get_groups(origin_url)
titles = []
bpm = []
for g in groups:
songs, songnames = get_songs(main_url + g)
titles.extend(songnames)
for s in songs:
info = get_bpm(main_url + s)
print(info)
bpm.append(info[1])
data = {
'title': titles,
'bpm': bpm
}
with open('data.json', 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=2)数据处理
我们利用 Python 中的pandas和matplotlib库来处理数据,并进行可视化处理。代码仅供参考。
提示
如果你没有安装这两个库,请先运行库安装命令:
pip install pandas matplotlibconda install pandas matplotlib:::
BPM 筛选
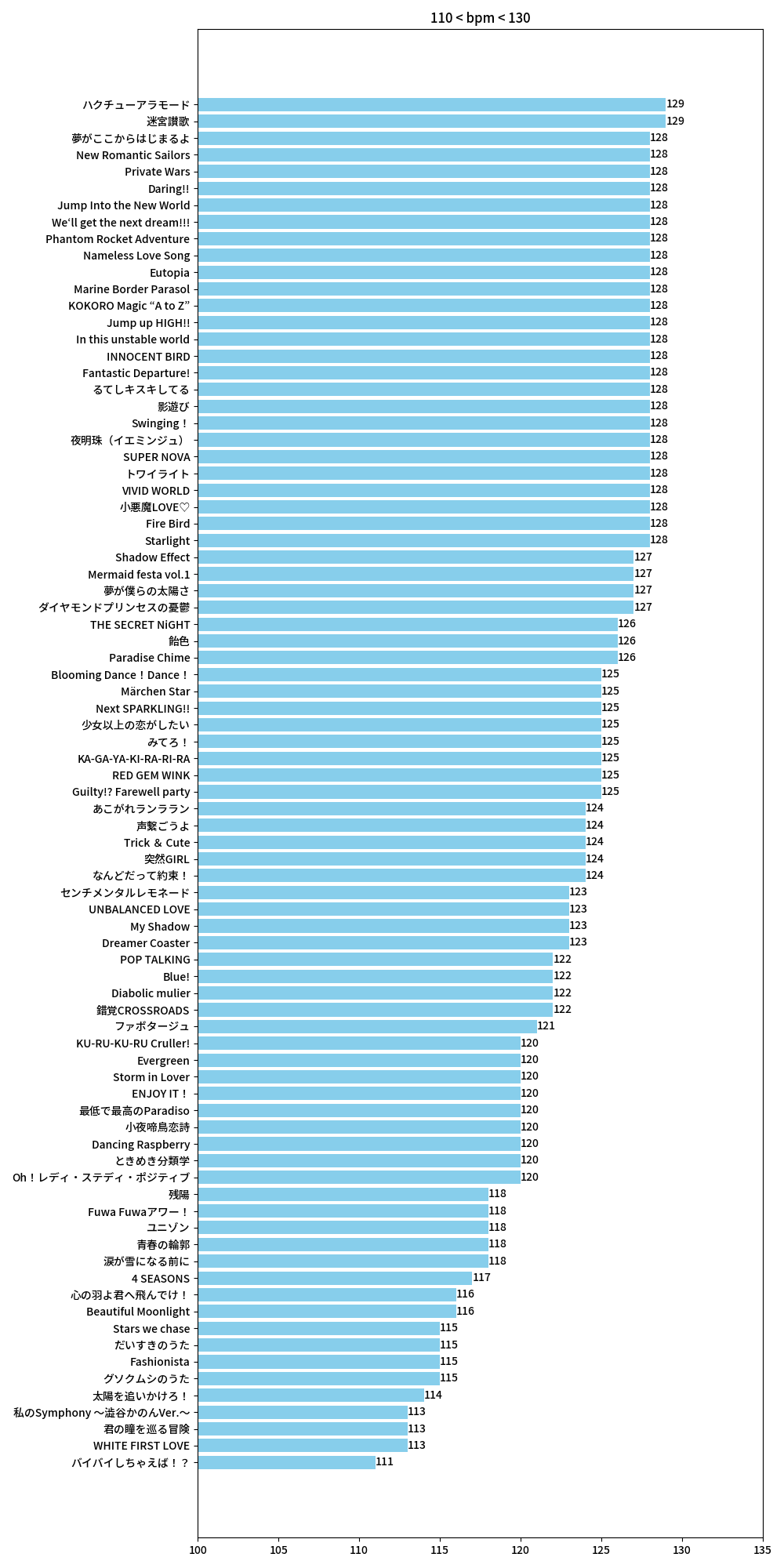
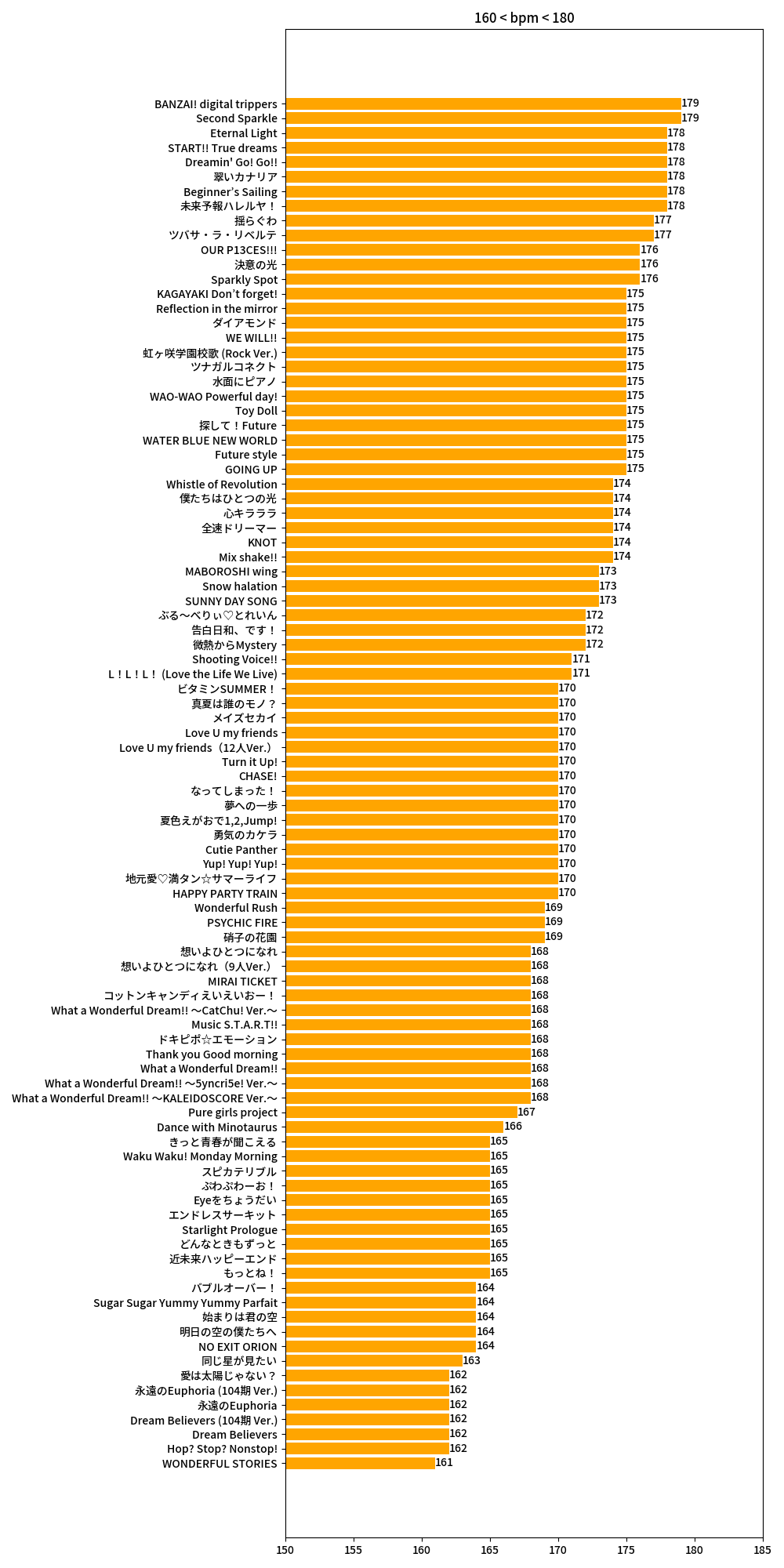
我们的目标是挑选走路和跑步时听的歌曲,因此需要筛选出 BPM 值与人类走路和跑步步频相同的歌曲。据查,人类走路和跑步的步频分别大致为 110~130 和 160~180,于是我们筛选出 BPM 值在这之间的歌曲即可。
注
筛选时将变 BPM 的歌曲排除在外,因为这也会打乱节奏。
def data_process():
with open('data.json', 'r', encoding='utf-8') as f:
data = json.load(f)
df = pd.DataFrame(data)
no_bpm = df[df['bpm'] == 'NO_BPM']
trans_bpm = df[df['bpm'].str.contains('→') | df['bpm'].str.contains('〜')]
valid_df = df[(df['bpm'] != 'NO_BPM') & (~df['bpm'].str.contains('→')) & (~df['bpm'].str.contains('〜'))]
walk_bpm = valid_df[(valid_df['bpm'].astype(int) > 110) & (valid_df['bpm'].astype(int) < 130)]
run_bpm = valid_df[(valid_df['bpm'].astype(int) > 160) & (valid_df['bpm'].astype(int) < 180)]
dic = {}
dic['暂无 bpm'] = [no_bpm['title'].tolist()]
dic['变 bpm'] = [trans_bpm['title'].tolist(), trans_bpm['bpm'].tolist()]
dic['110 < bpm < 130'] = [walk_bpm['title'].tolist(), walk_bpm['bpm'].tolist()]
dic['160 < bpm < 180'] = [run_bpm['title'].tolist(), run_bpm['bpm'].tolist()]
with open('result.json', 'w', encoding='utf-8') as f:
json.dump(dic, f, ensure_ascii=False, indent=2)绘制图像
这一步实际上可有可无,但是我们就讲究一个直观。😤
def draw_bpm():
plt.rcParams['font.family'] = 'Source Han Sans JP'
with open('result.json', 'r', encoding='utf-8') as f:
data = json.load(f)
walk = data['110 < bpm < 130']
run = data['160 < bpm < 180']
walk_df = pd.DataFrame({'title': walk[0], 'bpm': walk[1]})
run_df = pd.DataFrame({'title': run[0], 'bpm': run[1]})
walk_df['bpm'] = walk_df['bpm'].astype(int)
run_df['bpm'] = run_df['bpm'].astype(int)
walk_df = walk_df.sort_values(by='bpm')
run_df = run_df.sort_values(by='bpm')
plt.figure(figsize=(10, 20))
plt.barh(walk_df['title'], walk_df['bpm'], color='skyblue')
plt.title('110 < bpm < 130')
plt.xlim(100, 135)
for a, b in zip(walk_df['bpm'], range(len(walk_df))):
plt.text(a, b, a, ha='left', va='center', fontsize=10)
plt.tight_layout()
plt.savefig('bpm1.png')
plt.figure(figsize=(10, 20))
plt.barh(run_df['title'], run_df['bpm'], color='orange')
plt.title('160 < bpm < 180')
plt.xlim(150, 185)
for a, b in zip(run_df['bpm'], range(len(run_df))):
plt.text(a, b, a, ha='left', va='center', fontsize=10)
plt.tight_layout()
# save the figure
plt.savefig('bpm2.png')可视化的结果如下: