爬虫进阶——知网文献下载
注意
本篇博客所演示的爬虫程序仅用于学习研究,请勿用于窃取数据。
在去年关于通过 BPM 挑选歌曲的 文章 里,我用实际例子讲述了如何利用爬虫获取网站页面的 HTML 元数据,并从中获取对应信息(如链接、文字等)。然而,在更复杂的情况下,HTML 元数据所提供的信息远不能达到我们的需求,且网站本身还可能带有反爬机制,使我们的自动化爬虫工具运行不了几次就会被封锁。这该如何是好?
正巧,最近我也遇到了这样一个需要爬虫解决的问题:检索 中国知网 中某个关键词或期刊下的所有文献并下载。不同于 LLWiki,知网的反爬措施相当到位,我们不能用类似的方法进行文献检索下载。最明显的三个问题如下:
- 搜索界面/期刊内容界面的页面切换不会更改 URL,而是触发一个 JavaScript 操作。这使得我们无法通过输入特定的 URL 直接进入某一页,只能模拟点击按钮。
相关信息
反例,即页面切换会更改 URL 的情况如下:
以 Bangumi 为例,当我在全部动画列表中查看第二页时,可以看到 URL 变成了
https://bgm.tv/anime/browser?sort=rank&page=2
这里问号后的sort=rank和page=2都可以理解成该主页面(全部动画列表)下的附加条件(按排名排序,第二页)。如果直接访问上面这条 URL,能够直接进入列表第二页,无需多余点击操作。
文献下载界面的“pdf 下载”按钮对应链接并非直接指向文件本身,而是跳转到另一页面后再触发文件下载。这导致直接点击该按钮能够正常开启下载流程,但在页面的 HTML 元数据里访问该按钮对应的链接却无法触发。
多次重复操作后(即使是人类),网站会不可避免地弹出验证码。若需自动处理验证码,则难免会用到大量复杂的计算机视觉(CV)相关知识和代码实现。
不难看出,同去年相比,这次爬虫实现的难度骤增,各种已知或未知的障碍都需要一个个解决。因此,我们不得不拿出新工具、新方法,才足以应对这次的挑战。
准备
- Python 运行环境
- Selenium 库、BeautifulSoup 库
- WebDriver(Chrome 或者 firefox,文章中以 Chrome webdriver 为例)
其中,Selenium 库能够使计算机模拟人类访问浏览器时的各种操作,如鼠标点击、鼠标滚动等;而 WebDriver 则提供了一个 Web 服务器,方便对其进行自动化测试与运行。
重要
为节约篇幅,以下只介绍应对挑战的关键点。至于 Selenium 库的基本使用、通过 HTML 元素获取信息等基础方法步骤则被省略。
获取文献链接
通过搜索
以知网搜索界面为起点,其 URL 为https://kns.cnki.net/kns8s/defaultresult/index。通过多次搜索并观察,我们发现搜索界面可以通过在 URL 后加入关键词参数并访问实现快速搜索。
知网默认按“主题”搜索,若直接在 URL 后加入关键词,则会搜索主题为该关键词的文献;若要自定义搜索类型,则可以通过添加&korder=参数实现。具体的&korder=参数可以通过手动搜索后查看地址栏获得。如:
- 主题为丁真:
https://kns.cnki.net/kns8s/defaultresult/index?kw=丁真 - 作者为丁真:
https://kns.cnki.net/kns8s/defaultresult/index?kw=丁真&korder=AU
在搜索结果页面,我们需要提取文献链接进行后续处理。经分析页面 HTML 元数据,发现所有文献标题链接都有统一的类名:<a class="fz14">,因此我们可以使用 BeautifulSoup 库,直接提取所有.fz14类元素的链接即可。通过该元素的信息,我们保存了文献名、年代、文献详情页链接。
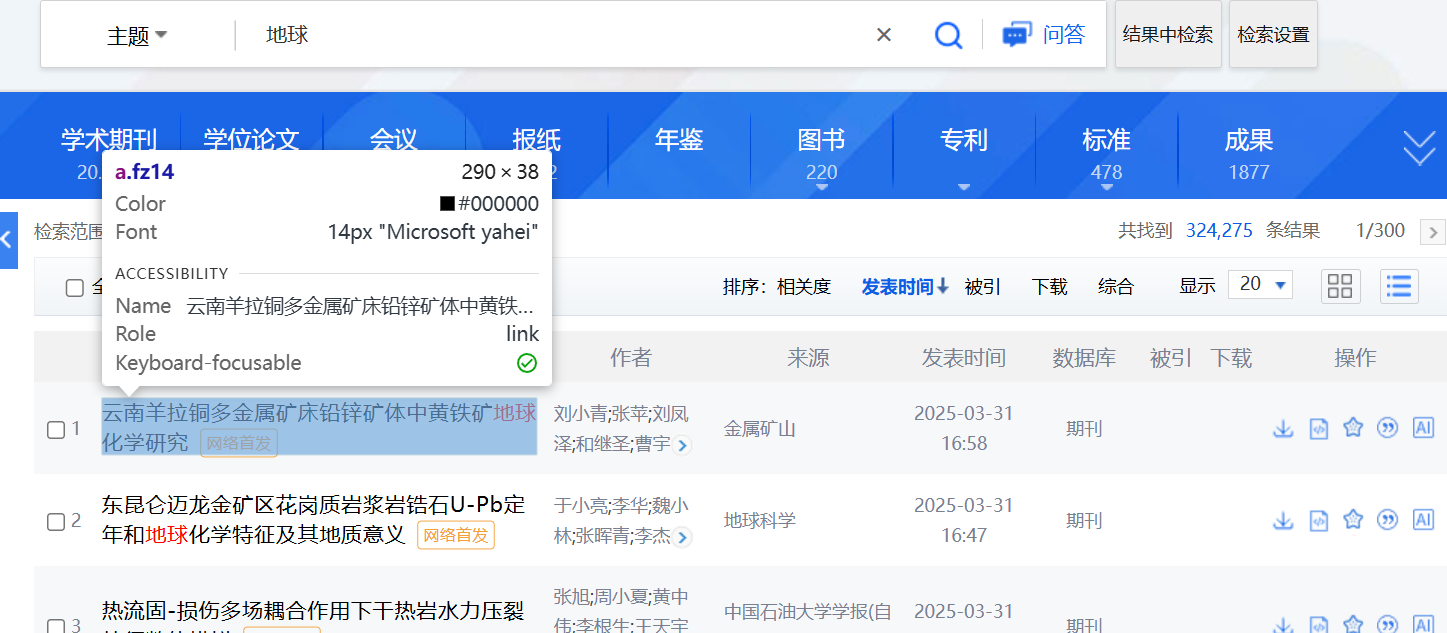
知网默认每页显示 20 条结果,为提高爬取效率,我们可以将其切换为每页 50 条。页面上有一个控制分页数量的元素<div id="perPageDiv">,我们利用 Selenium 模拟点击此元素并选择 50 条即可。
# 切换每页显示数量
per_page_div = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, 'perPageDiv'))
)
per_page_div.click()
page_50 = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, 'li[data-val="50"] a'))
)
page_50.click()当需要的数据超过单页数量时,我们需要自动翻页获取后续页面内容。知网的“下一页”按钮使用了如同<a id="PageNext">的元素表示,通过 Selenium 可以轻松模拟点击翻页,重复此过程直到达到我们设定的结果数量即可。
# 模拟鼠标点击翻页
next_button = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, 'PageNext'))
)
if 'disabled' not in next_button.get_attribute('class'):
next_button.click()# Made by Ofnoname && Wanakachi
import os
import time
import logging
from typing import List
from bs4 import BeautifulSoup
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
# 配置
DEBUG = False
CHROME_DRIVER_PATH = r'C:/Program Files/chromedriver-win64/chromedriver.exe'
SAVE_DIR = 'saves'
LINK_DIR = 'links'
KEYWORDS = {'相对论'} # 待搜索关键词集合
RESULT_COUNT = 60 # 每个关键词搜索结果数量
driver = None
# 配置日志记录
logging.basicConfig(
level=logging.DEBUG if DEBUG else logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
def ensure_directory_exists(directory: str) -> None:
"""
确保指定目录存在,若不存在则创建。
"""
if not os.path.exists(directory):
os.makedirs(directory)
logging.debug(f"目录 {directory} 创建成功。")
else:
logging.debug(f"目录 {directory} 已存在。")
def load_chrome_driver() -> webdriver.Chrome:
"""
初始化并返回 Chrome 驱动实例,同时配置下载目录等参数。
"""
service = Service(CHROME_DRIVER_PATH)
options = webdriver.ChromeOptions()
if not DEBUG:
options.add_argument('--headless')
options.add_argument("--disable-gpu")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--enable-unsafe-swiftshader")
options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36")
# 设置下载目录,并确保目录为绝对路径
abs_save_dir = os.path.abspath(SAVE_DIR)
options.add_experimental_option("prefs", {
"download.prompt_for_download": False,
"download.directory_upgrade": True,
"plugins.always_open_pdf_externally": True,
"safebrowsing.enabled": False,
"download.default_directory": abs_save_dir,
})
driver_instance = webdriver.Chrome(service=service, options=options)
# 绕过 webdriver 检测
driver_instance.execute_script("Object.defineProperty(navigator, 'webdriver', {get: () => undefined})")
driver_instance.get('https://kns.cnki.net/kns8s/defaultresult/index')
driver_instance.refresh()
return driver_instance
def scrape_keyword(keyword: str, result_count: int) -> None:
"""
根据关键词爬取搜索结果链接,并保存到指定文件中。
:param keyword: 搜索关键词
:param result_count: 需要爬取的结果数量
"""
url = f'https://kns.cnki.net/kns8s/defaultresult/index?kw={keyword}'
driver.get(url)
time.sleep(2)
links: List[str] = []
dates: List[str] = []
names: List[str] = []
try:
per_page_div = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, 'perPageDiv'))
)
per_page_div.click()
# 等待排序列表加载
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'ul.sort-list'))
)
# 找到“50”这一分页选项并点击
page_50_locator = (By.CSS_SELECTOR, 'li[data-val="50"] a')
page_50 = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable(page_50_locator)
)
page_50.click()
time.sleep(2)
except Exception as e:
logging.error(f"点击分页选项时出错:{e}")
while len(links) < result_count:
page_source = driver.page_source
soup = BeautifulSoup(page_source, 'html.parser')
fz14_links = soup.select('.fz14')
date_cells = soup.select('.date')
# 遍历当前页面的所有搜索结果
for link_tag, date_cell, name_tag in zip(fz14_links, date_cells, fz14_links):
if link_tag.has_attr('href'):
date_text = date_cell.get_text(strip=True)
year = date_text.split('-')[0]
links.append(link_tag['href'])
dates.append(year)
names.append(name_tag.get_text(strip=True))
if len(links) >= result_count:
break
if len(links) < result_count:
try:
next_button = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, 'PageNext'))
)
if 'disabled' in next_button.get_attribute('class'):
break
next_button.click()
time.sleep(1.5)
except Exception as e:
logging.error(f"翻页失败: {e}")
break
# 保存结果到文件,文件名以关键词命名,后缀设为 .txt
output_file = os.path.join(LINK_DIR, f"{keyword}.txt")
with open(output_file, 'w', encoding='utf-8') as file:
for link, year, name in zip(links, dates, names):
file.write(f'{name} -||- {year} -||- {link}\n')
logging.info(f"主题为 {keyword} 的链接已保存到 {output_file}")
def main() -> None:
"""
主函数:确保目录存在、初始化驱动、依次爬取各关键词,并在结束后关闭驱动。
"""
global driver
# 确保保存下载文件和链接文件的目录存在
ensure_directory_exists(SAVE_DIR)
ensure_directory_exists(LINK_DIR)
driver = load_chrome_driver()
try:
for keyword in KEYWORDS:
scrape_keyword(keyword, RESULT_COUNT)
finally:
if driver:
driver.quit()
logging.info("驱动已关闭。")
if __name__ == "__main__":
main()通过期刊
若需要检索已知期刊中包含的文献,则通过期刊检索更为方便。这里的 URL 起点是https://navi.cnki.net/knavi/。
注
与搜索界面不同的是,使用默认的 Chrome WebDriver 进入该网站时可能会被识别并拦截,因此我们需要特殊的浏览器伪装措施。
在这里,我们采用了 undetected_chromedriver 库,该库内置了多种伪装方法,可以有效绕过一般的反爬虫检测机制,api 和原版基本相同。
该检索界面不支持通过 URL 参数直接搜索,必须手动输入关键词或 ISSN 进行检索。为确保搜索结果唯一且准确,推荐使用期刊的 ISSN 号。
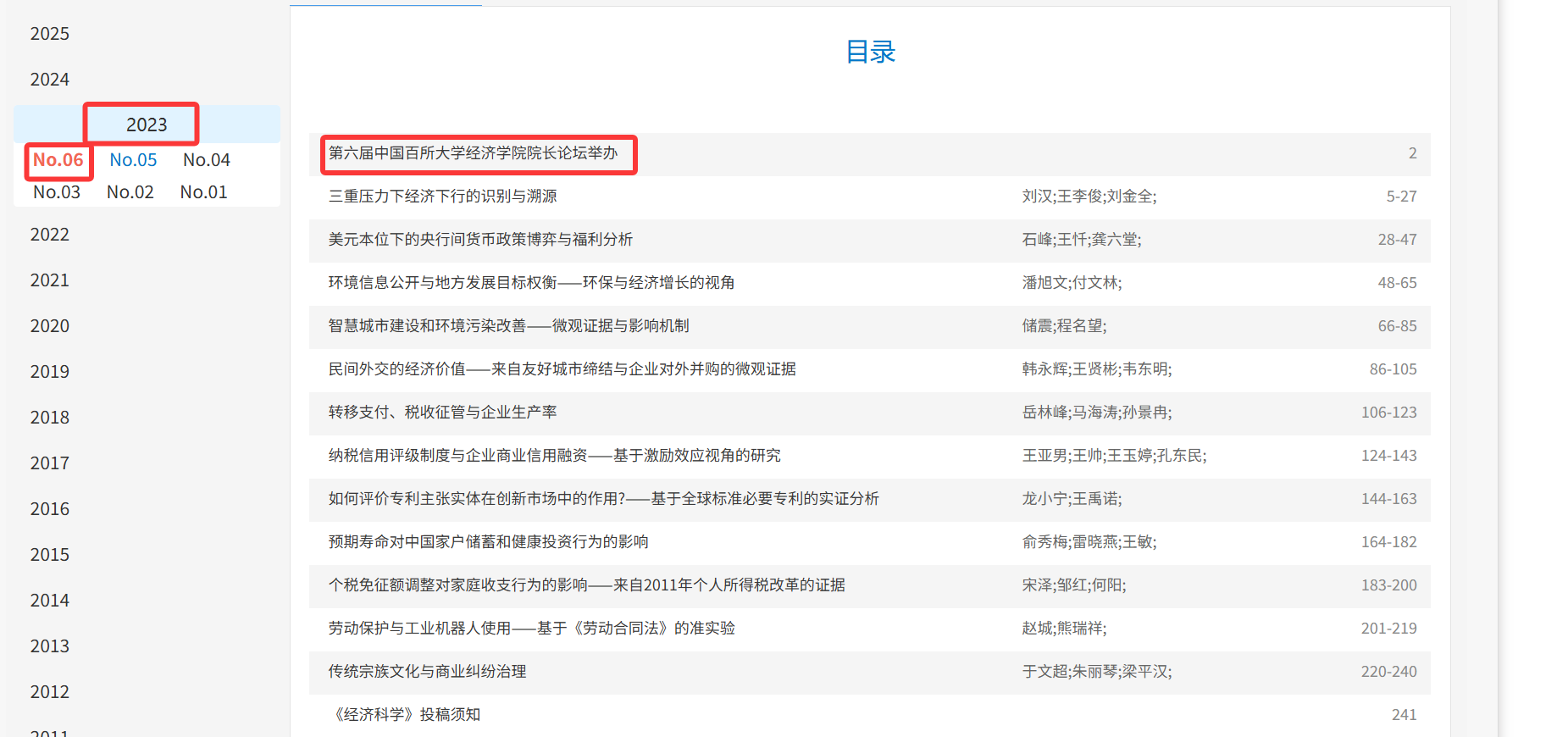
进入期刊页面后,文献列表会按照年份和期号依次展示在左侧导航栏中。我们展开列表,并逐一点击该年份下的各期刊选项,最后从右侧的<dl id="CataLogContent">元素区域提取文献链接。
# Made by Ofnoname && Wanakachi
import logging
import os
import time
from typing import List, Tuple
import pandas as pd
import undetected_chromedriver as uc
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from seleniumwire import webdriver
# 配置
DEBUG = True
CHROME_DRIVER_PATH = r'C:/Program Files/chromedriver-win64/chromedriver.exe'
SAVE_DIR = 'saves'
LINK_DIR = 'links'
EXCEL_FILE = '测试期刊.xls'
YEAR_RANGE = [2014, 2022]
# 配置日志记录
logging.basicConfig(
level=logging.DEBUG if DEBUG else logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
def ensure_directory_exists(directory: str) -> None:
"""
确保指定目录存在,若不存在则创建。
"""
if not os.path.exists(directory):
os.makedirs(directory)
logging.debug(f"目录 {directory} 创建成功。")
else:
logging.debug(f"目录 {directory} 已存在。")
def load_chrome_driver(use_undetected: bool = True) -> webdriver.Chrome:
"""
加载 ChromeDriver,并配置相关选项。
:param use_undetected: 如果为 True,则使用 undetected_chromedriver,否则使用常规 webdriver.Chrome。
:return: Chrome WebDriver 实例。
"""
service = Service(CHROME_DRIVER_PATH)
options = webdriver.ChromeOptions()
if use_undetected:
driver_instance = uc.Chrome(options=options)
else:
driver_instance = webdriver.Chrome(service=service, options=options)
driver_instance.execute_script("Object.defineProperty(navigator, 'webdriver', {get: () => undefined})")
return driver_instance
def process_journal(name: str, issn: str, year_range: List[int]) -> None:
"""
根据期刊名称和 ISSN 检索期刊,并收集指定年份的文章链接,将链接保存到文件中。
:param name: 期刊名称
:param issn: 期刊 ISSN
:param year_range: [起始年份, 结束年份]
"""
driver = load_chrome_driver(use_undetected=True)
try:
driver.get('https://navi.cnki.net/')
time.sleep(0.5)
logging.info(f"正在检索期刊: {name},ISSN: {issn},年份范围: {year_range[0]}-{year_range[1]}")
# 选择检索方式为 ISSN
select_element = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, "txt_1_sel"))
)
option_elements = select_element.find_elements(By.TAG_NAME, "option")
for option in option_elements:
if option.text.strip() == "ISSN":
option.click()
break
# 输入 ISSN
input_element = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, "txt_1_value1"))
)
input_element.clear()
input_element.send_keys(issn)
# 点击搜索按钮
button_element = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, "btnSearch"))
)
button_element.click()
# 等待页面加载完成并点击第一个期刊
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, ".re_bookCover"))
).click()
time.sleep(0.5)
# 切换到新打开的窗口
driver.switch_to.window(driver.window_handles[-1])
# 遍历指定年份,收集期刊文章链接
for year in range(year_range[0], year_range[1] + 1):
logging.info(f"正在检索 {name} {year} 年的期刊链接")
year_id = f"{year}_Year_Issue"
year_element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, year_id))
)
# 展开年份下拉
dt_element = WebDriverWait(year_element, 10).until(
EC.element_to_be_clickable((By.TAG_NAME, "dt"))
)
dt_element.click()
issue_elements = year_element.find_elements(By.CSS_SELECTOR, "dd a")
all_links: List[str] = []
for issue_element in issue_elements:
# 等待期号链接可用
WebDriverWait(driver, 10).until(lambda d: issue_element.is_enabled() and issue_element.is_displayed())
issue_element.click()
time.sleep(0.5)
link_elements = WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#CataLogContent span.name a"))
)
for link_element in link_elements:
link = link_element.get_attribute("href")
if link:
all_links.append(link)
time.sleep(0.5)
# 保存链接到文件
output_file = os.path.join(LINK_DIR, f"{name}_{year}.txt")
with open(output_file, 'w', encoding='utf-8') as f:
for link in all_links:
f.write(link + '\n')
logging.info(f"保存链接到文件: {output_file}")
except Exception as e:
logging.error(f"处理期刊 {name} 时发生错误: {e}", exc_info=True)
finally:
driver.quit()
logging.debug("驱动已关闭。")
def load_journal_list(excel_file: str) -> List[Tuple[str, str]]:
"""
从 Excel 文件中加载期刊列表。请修改这里的数据加载,根据你组织的待爬列表而定。
:param excel_file: Excel 文件路径
:return: 包含 (期刊名称, ISSN) 元组的列表
"""
try:
df = pd.read_excel(excel_file, header=None)
journal_list = [(str(row[0]).strip(), str(row[1]).strip()) for row in df.values if pd.notna(row[0])]
logging.debug(f"加载期刊数量: {len(journal_list)}")
return journal_list
except Exception as e:
logging.error(f"读取 Excel 文件 {excel_file} 失败: {e}")
return []
def main() -> None:
"""
主函数:确保目录存在、加载期刊列表,并依次处理每个期刊。
"""
ensure_directory_exists(SAVE_DIR)
ensure_directory_exists(LINK_DIR)
journals = load_journal_list(EXCEL_FILE)
for name, issn in journals:
process_journal(name, issn, YEAR_RANGE)
time.sleep(2)
if __name__ == "__main__":
main()下载文献
最后是最麻烦的一步。这里困难的点集中在处理各种验证码上。
我们不采用利用 CV 强行通过验证码本身的方式,这会大幅增加代码的完成难度,且效果不一定显著。而是选择想办法绕过验证码,或者尽量规避验证码的出现。据多次观察,我们发现验证码会出现在两个地方:打开文献详情页时,以及点击下载弹出新窗口时。
前者是一个纯前端验证码,运行driver.execute_script("redirectNewLink()")页面函数即可简单将其跳过,屡试不爽。
后者就比较难办了,完全没有办法绕过,那么只能尽量规避它的出现。为此,我们设计了一套 “拟人”算法,将该验证码的出现概率尽量降低。我们观察到的“人机工学”现象,以及该“拟人”算法的主要思路如下:
- 直接进入文献详情界面极容易触发验证码。
- 控制浏览器进行一些无意义的搜索和浏览,再进入详情界面,降低验证码的出现概率。
- 在文献详情页打开后立即点击下载按钮容易触发验证码。
- 控制浏览器在同一个文献界面多停留、多刷新后再点击下载。
- 短时间下载大量文献会迅速批量触发验证码。
- 控制浏览器下载一定数量的文献后“休息”一下,重启浏览器并模拟人类“闲逛”后再进行下载。
def simulate_human_behavior(driver: webdriver.Chrome) -> None:
"""
模拟人类行为闲逛,降低被网站检测为机器人的风险
"""
try:
# 随机页面闲逛
driver.get('https://kns.cnki.net/kns8s/defaultresult/index')
time.sleep(random.uniform(1, 1.5))
driver.get('https://kns.cnki.net/kns8s/defaultresult/index?kw=丁真')
time.sleep(random.uniform(1, 1.5))
try:
next_button = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, 'PageNext'))
)
if 'disabled' not in next_button.get_attribute('class'):
next_button.click()
except Exception as e:
logging.debug(f"Page next click failed in human behavior simulation: {e}")
el = ('https://kns.cnki.net/kcms2/article/abstract?v='
'jNHD1hIvxn3V4QTDlEMKElsHKaTntLnuqQcAeWVTldLPFBn7iT-1Tm4UqqAiMvAEyHpC5baI1wNaLNYpxJrWNLLA-'
'qwDCdqTs7Q_qbXKpcOcTkzjDVW1nndiqngcWd2EQjyOwhwnX44UVtGVXou0tJJ1uxIBDd_iR7mmJhaA88A=&uniplatform=NZKPT')
driver.get(el)
# 在详情页反复刷新
for _ in range(24):
driver.refresh()
time.sleep(random.uniform(0.18, 0.4))
except Exception as e:
logging.error(f"Error in human behavior simulation: {e}")即使运用“拟人”算法,还是会有小概率出现漏网之鱼——触发验证码。为了做到万无一失,我们为每篇文章设置了最大重试次数,触发验证码的文献会被记录移到队列末,在一遍流程结束后再统一进行重试。只要在不超过最大重试次数的范围内下载成功即可。
以上是针对稳定性和可用性的措施,至于效率上的优化,我们可以利用并发线程同时打开多个浏览器,并且视情况采用无头模式(headless),不显示浏览器 UI,以提高效率。
# Made by Ofnoname && Wanakachi
import os
import random
import time
import sys
import logging
from concurrent.futures import ThreadPoolExecutor, as_completed
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver import ActionChains
# 全局配置
DEBUG = True
HEADLESS = False
CHROME_DRIVER_PATH = r'C:/Program Files/chromedriver-win64/chromedriver.exe' # 请根据实际情况修改
SAVE_DIR = 'saves'
LINK_DIR = 'links'
FILE_TYPE = 'pdf' # 可选 'pdf' 或 'caj'
MAX_WORKERS = 2 # 同时处理的任务数
BATCH_SIZE = 45 # 每下载 BATCH_SIZE 篇文章休息一次
MAX_RETRIES = 3 # 最大重试次数
# 日志配置
logging.basicConfig(
level=logging.DEBUG if DEBUG else logging.INFO,
format='%(asctime)s [%(levelname)s] %(message)s',
handlers=[logging.StreamHandler(sys.stdout)]
)
def ensure_directory(directory: str) -> None:
"""确保目录存在,不存在则创建。"""
if not os.path.exists(directory):
os.makedirs(directory)
logging.debug(f"Directory created: {directory}")
def load_chrome_driver(download_dir: str = None) -> webdriver.Chrome:
"""
加载并配置一个新的 ChromeDriver 实例
:param download_dir: 指定下载目录(绝对路径)
:return: 配置好的 WebDriver 实例
"""
options = webdriver.ChromeOptions()
service = Service(CHROME_DRIVER_PATH)
if HEADLESS:
options.add_argument('--headless')
options.add_argument('--disable-gpu')
options.add_argument('--disable-software-rasterizer')
options.add_argument('--disable-images')
options.add_argument('--disable-extensions')
options.add_argument('--window-size=1920x1080')
prefs = {
"download.default_directory": os.path.abspath(download_dir) if download_dir else os.path.abspath(SAVE_DIR),
"download.prompt_for_download": False,
"download.directory_upgrade": True,
"plugins.always_open_pdf_externally": True,
"safebrowsing.enabled": False,
}
options.add_experimental_option("prefs", prefs)
driver = webdriver.Chrome(service=service, options=options)
driver.execute_script("Object.defineProperty(navigator, 'webdriver', {get: () => undefined})")
return driver
def simulate_human_behavior(driver: webdriver.Chrome) -> None:
"""
模拟人类行为闲逛,降低被网站检测为机器人的风险
"""
try:
driver.get('https://kns.cnki.net/kns8s/defaultresult/index')
time.sleep(random.uniform(1, 1.5))
driver.get('https://kns.cnki.net/kns8s/defaultresult/index?kw=丁真')
time.sleep(random.uniform(1, 1.5))
try:
next_button = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, 'PageNext'))
)
if 'disabled' not in next_button.get_attribute('class'):
next_button.click()
except Exception as e:
logging.debug(f"Page next click failed in human behavior simulation: {e}")
el = ('https://kns.cnki.net/kcms2/article/abstract?v='
'jNHD1hIvxn3V4QTDlEMKElsHKaTntLnuqQcAeWVTldLPFBn7iT-1Tm4UqqAiMvAEyHpC5baI1wNaLNYpxJrWNLLA-'
'qwDCdqTs7Q_qbXKpcOcTkzjDVW1nndiqngcWd2EQjyOwhwnX44UVtGVXou0tJJ1uxIBDd_iR7mmJhaA88A=&uniplatform=NZKPT')
driver.get(el)
for _ in range(24):
driver.refresh()
time.sleep(random.uniform(0.18, 0.4))
except Exception as e:
logging.error(f"Error in human behavior simulation: {e}")
def attempt_download(driver: webdriver.Chrome, link: str, index: int, name: str, year: str) -> bool:
"""
尝试下载单篇文章,支持重试机制
:return: 下载成功返回 True,否则返回 False
"""
for attempt in range(1, MAX_RETRIES + 1):
try:
driver.get(link)
time.sleep(1)
try:
driver.execute_script("redirectNewLink()")
except Exception:
pass
for _ in range(2):
driver.refresh()
time.sleep(1)
try:
driver.execute_script("redirectNewLink()")
except Exception:
pass
time.sleep(0.5)
css_selector = '.btn-dlpdf a' if FILE_TYPE == 'pdf' else '.btn-dlcaj a'
link_element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, css_selector))
)
download_link = link_element.get_attribute('href')
if download_link:
ActionChains(driver).move_to_element(link_element).click(link_element).perform()
driver.switch_to.window(driver.window_handles[-1])
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.TAG_NAME, 'html'))
)
if "拼图校验" in driver.page_source:
logging.warning(f"{name} {year} article {index+1}: captcha triggered on attempt {attempt}")
driver.close()
driver.switch_to.window(driver.window_handles[0])
if attempt < MAX_RETRIES:
logging.info(f"{name} {year} article {index+1}: retrying (attempt {attempt})")
time.sleep(random.uniform(1, 2.5))
for _ in range(4):
driver.refresh()
time.sleep(random.uniform(0.8, 1.0))
continue
else:
logging.info(f"{name} {year} article {index+1} downloaded successfully on attempt {attempt}")
driver.switch_to.window(driver.window_handles[0])
return True
except Exception as e:
logging.error(f"{name} {year} article {index+1}: error on attempt {attempt}: {e}")
time.sleep(random.uniform(2, 4))
return False
def download_for_year(name: str, year: str, links: list) -> None:
"""
为指定期刊和年份下载文章,失败的链接会进行二次尝试
"""
output_dir = os.path.join(SAVE_DIR, name, str(year))
ensure_directory(output_dir)
logging.info(f"Starting download for {name} {year}, saving to {output_dir}")
driver = None
num_success = 0
num_skipped = 0
skipped_links = []
try:
for idx, link in enumerate(links):
if idx % BATCH_SIZE == 0:
logging.info(f"{name} {year}: processed {idx} articles, taking a break...")
time.sleep(5)
if driver:
driver.quit()
driver = load_chrome_driver(download_dir=output_dir)
simulate_human_behavior(driver)
if not attempt_download(driver, link, idx, name, year):
num_skipped += 1
skipped_links.append(link)
else:
num_success += 1
# 对未下载成功的文章进行重新下载尝试
if skipped_links:
logging.info(f"{name} {year}: retrying {len(skipped_links)} skipped articles...")
for idx, link in enumerate(skipped_links):
if idx % BATCH_SIZE == 0:
logging.info(f"{name} {year}: reprocessing {idx} skipped articles, taking a break...")
time.sleep(5)
if driver:
driver.quit()
driver = load_chrome_driver(download_dir=output_dir)
simulate_human_behavior(driver)
if attempt_download(driver, link, idx, name, year):
num_success += 1
num_skipped -= 1
else:
logging.error(f"{name} {year}: article skipped after retries: {link}")
except Exception as e:
logging.error(f"Error processing {name} {year}: {e}")
finally:
if driver:
driver.quit()
logging.info(f"Finished {name} {year}: Success: {num_success}, Skipped: {num_skipped}")
def process_txt_file(file_path: str) -> None:
"""
处理 link_dir 目录下的单个 txt 文件,文件名格式要求为:<期刊名>_<年份>.txt
"""
base_name = os.path.basename(file_path)
try:
# 这里假定文件名格式为:name_year.txt,其中 year 为纯数字部分
name_part, year_part = base_name.rsplit('_', 1)
year = year_part.split('.')[0]
except Exception as e:
logging.error(f"Error parsing file name {base_name}: {e}")
return
with open(file_path, 'r', encoding='utf-8') as f:
links = [line.strip() for line in f if line.strip()]
logging.info(f"Processing file {base_name} with {len(links)} links")
download_for_year(name_part, year, links)
def main() -> None:
"""
主函数:扫描 link_dir 目录中所有 txt 文件,并利用线程池并发处理下载任务
"""
if not os.path.exists(LINK_DIR):
logging.error(f"Link directory {LINK_DIR} does not exist")
return
txt_files = [os.path.join(LINK_DIR, f) for f in os.listdir(LINK_DIR) if f.endswith('.txt')]
if not txt_files:
logging.error("No txt files found in link directory.")
return
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor:
futures = {executor.submit(process_txt_file, file): file for file in txt_files}
for future in as_completed(futures):
file = futures[future]
try:
future.result()
logging.info(f"Completed processing {file}")
except Exception as e:
logging.error(f"Error processing {file}: {e}")
if __name__ == '__main__':
main()